annoy ANN算法 调参
2024-04-19 09:27:09
search_k
serach_k越大,越准确,但是要在时间和准确率之间取个trade off
During the query it will inspect up to search_k nodes which defaults to n_trees * n
build on memory or disk
build on disk
disk上build的时候,树的node个数是所有样本个数的大约2倍,(作者说无法获得多少颗树,困==
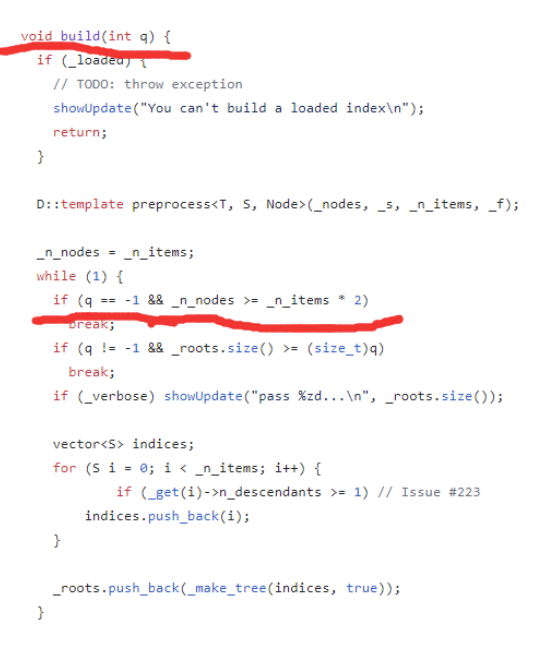

build on memory
指定颗的树数(5)

差别也不是很大,感觉可能是tencent 那个embedding训练的实在太好了
最新文章
- Spring基础
- GitHub使用教程
- struts2学习笔记之十:文件上传
- Android网页浏览器的开发
- aws在线技术峰会笔记-电商解决方案
- 32、shiro 框架入门三
- 【iOS】Quartz2D简单介绍
- windows8.1安装
- C# 委托的”四步走“
- My Eclipse 自动提示
- Fedora 开启 ssh
- JAVAEE学习——struts2_02:结果跳转方式、访问servletAPI方式、获得参数以及封装和练习:添加客户
- 搭建ruby环境
- HTML/CSS 常用单词整理
- idea将maven项目打包成war包
- Hadoop数据类型
- 如何消除手机设置的字体大小对Cordova app(Android)界面font-size的影响
- 微信小程序奇奇怪怪的语法
- Redis数据类型和常用命令
- layui怎么通过jquery去控制一个本身已经隐藏的div让他通过点击显示出来