Xgboost总结
从决策树、随机森林、GBDT最终到XGBoost,每个热门算法都不是孤立存在的,而是基于一系列算法的改进与优化。决策树算法简单易懂可解释性强,但是过拟合风险很大,应用场景有限;随机森林采用Bagging采样+随机属性选择+模型集成的方法解决决策树易过拟合的风险,但是牺牲了可解释性;GBDT在随机森林的基础上融合boosting的思想建立树与树之间的联系,使森林不再是互相独立的树存在,进而成为一种有序集体决策体系;XGBoost在GBDT的基础上更进一步,将每轮迭代的目标函数中加入正则项,进一步降低过拟合的风险。相对于GBDT启发式的迭代原则,XGBoost的优化准则完全基于目标函数的最小化推导,并采用了二阶泰勒展开,使自定义损失函数成为可能。除此之外,XGBoost同样继承了随机采样、随机属性选择、学习率等算法实用技巧,与此同时实现了属性计算级别的并行化。可以说,XGBoost是一种集大成的机器学习算法。
几个误区:
- 在目标函数中增加正则项是XGBoost的一项比较重要的改进,因为GBDT中的正则化主要依靠一些工程措施,局限性与可操作性较差。XGBoost则直接将正则项加入到目标函数中,这样一来,每一轮的迭代均在数学层面进行了正则化,效果与可操作性大大提升。
XGB是一个具有可扩展性的树提升算法机器学习系统,它的可扩展性体现在以下四个方面:
- 模型的scalability,弱分类器除cart外也支持lr和linear
- 策略的scalability,可以支持不同的loss functions,来优化效果,只要一、二阶可导即可
- 算法的scalability,做了很多细节工作,来优化参数学习和迭代速度,特征压缩技,bagging学习中的特征抽样,特征选择与阈值分裂的分位方法和并行方法等
- 数据的scalability,因为3种的优化,支持B级别的快速训练和建模;同时也因为加上了正则项和随机特征抽样,减少了过拟合问题
1. Xgboost的算法的流程?
(1)引入
回归树:每个叶子节点都有一个分数,预测的结果就是所有树的分数之和
输入:age,gender,occupation,...
输出:判断一个人是否喜欢打游戏
xgboost的基本思想就是一种提升的思想,后一个模型在前一个模型的基础上再进行预测,弥补前一个模型做的不好的地方。例如真实值是100,第一颗树的预测值是95,还有5的误差,然后我们再用第二颗树再预测,预测出来3这样两颗树的综合结果就是98,然后依次类推。
 给定数据集,n个实例,m个特征:
给定数据集,n个实例,m个特征:

树集成模型(下图所示)使用K个函数的累加和来预测输出;

这里有几个疑问:
- 每一棵树的分支依据是如何确定的?(比如先分age,再分性别) 【贪心:从所有特征中找最好的】
- 每一棵树的分支分到哪里为止?(比如is male?下面还要不要分支?)【可以根据公式判断是否要继续分裂,见(3)节公式4】
- 每棵树的叶子节点的权重分值是如何确定的?(为什么有的是2,有的是0.9,有的是-1)【对于固定的树结构,可以根据(3)节公式2得到叶子的最优权重】
- 树的棵数是如何确定的,多少棵树是最合适的?
(2)目标函数
目标函数:

这里l是一个可微的凸损失函数,测量预测值和目标值的不同。 是k颗树的正则项,用于抑制模型的复杂度防止过拟合。当正则项的参数是0时,上述目标函数就是一个传统的梯度树提升模型。
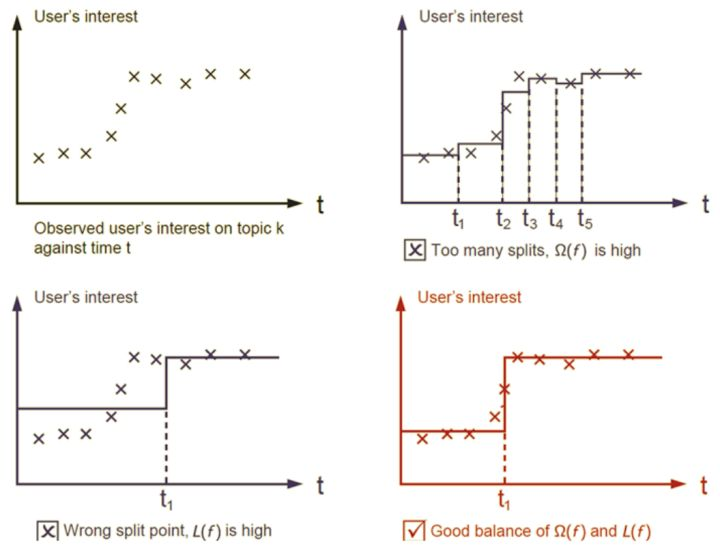
左上角描绘的是用户随着时间的变化对某话题的感兴趣程度的变化,如果使用step function来建模,可以看到右上角的模型基本上拟合到每一个数据点,然而也可以看到它太复杂了,也就是模型复杂度太高;而对于左下角模型,它虽然比较简单,但是很多数据都没有拟合到;最后看看右下角的模型,它简单,而且基本拟合到所有数据点。因此我们说右下角的模型是最好的,对于一个机器学习的模型的通用原则是:简单并且准确。模型往往需要在简单和准确之中做一个折中,这种折中也成为偏差-方差的折中(bias-variance tradeoff)。
(3)梯度树提升
上述目标函数的参数本身是函数,这样使用传统的优化方法是不能优化到最优值的。相反,模型的训练时采用加法的形式来训练的,形式上,使用 作为第i个实例在第t词迭代中的预测值,我们需要添加ft来最小化下面的目标函数(针对第t轮的迭代的目标函数):
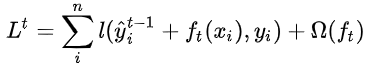
注意,上式中第t-1轮的预测是已知的,也就是已经有了t-1棵树。
然后使用二阶泰勒展开得到(具体为什么能使用泰勒公式二次展开看这里):
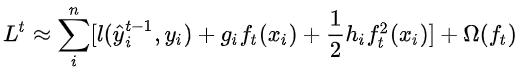
其中:
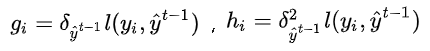
由于t-1轮的结果是已知的,可以去掉,去掉后公式如下 :
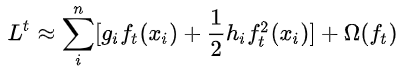
可以看出公式仅依赖于g和h,也就是一阶导和二阶导,这也是为什么XGBoost支持的自定义损失函数必须二阶可导的原因。
进一步将正则化项展开并合并,得:
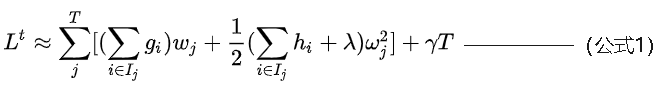
可以看出,对上式求最小值可以得到wj的最优值,如下:
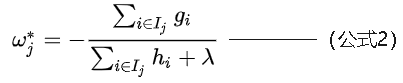 计算叶子节点值
计算叶子节点值
公式2计算这棵树的最小值如下:
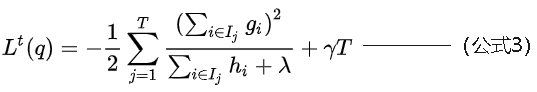
公式3可以用来衡量一个树的结构质量(也就是学习的这棵树对总体结果有没有提升),可以将公式3理解为对决策树不纯度的衡量,也就是说可以使用公式3作为树节点分裂的依据,即衡量节点在分裂前后公式3对应数值的大小来判断是否需要分裂,如分裂前公式3值为100,按照特征1分裂后两节点公式3的值相加为90,按照特征2分裂后两节点公式3的值相加为80,那么树就将按照特征2分裂。分裂增益公式如下:
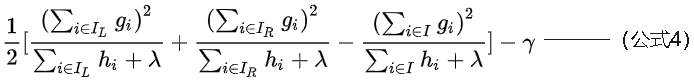 基树分裂的依据(判断该分裂节点是不是应该分裂)
基树分裂的依据(判断该分裂节点是不是应该分裂)
结合公式2与4,就可以从第t-1棵树创建第t棵树。
从公式4上可以看出 的存在可以在一定程度上控制分裂的程度。下图展示了如何计算一棵树的分值:树的计算分值越低,说明这个树的结构越好。

综上所述,XGBoost的建树过程、boosting过程均是以目标函数为基础进行的,一切操作的衡量标准均是最小化目标函数,其采用的算法策略依然是贪心策略。由于引入了泰勒二阶展开,建树与boosting的过程仅依赖于损失函数的一阶导数与二阶导数,公式比较清晰易懂。整个推导使用二阶泰勒展开的一个最大好处是:支持自定义损失函数,仅要求损失函数二阶可导。另外XGBoost将正则项加入到了目标函数中,保证了每次的迭代均对模型的复杂度进行了对冲,有效降低了过拟合发生的可能性。
(4)收缩和列采样
在防止模型过拟合方面,除了使用正则化项,收缩和列采样也经常使用。收缩规模在树提升的每一步迭代中通过因子 逐步增加收缩权重,这和随机梯度下降的学习率相似。收缩技术降低了每一个单个的树和叶子节点对之后要学习的树结构的影响。列采样在随机森林中被使用,它除了能防止过拟合还能加块并行算法的计算速度。
2. 如何选择每个特征的分裂点 ?
(1)贪心选特征
在树学习中,一个关键问题是如何找到每一个特征上的分裂点,比如在本文的例子中,age的分裂节点是15岁,而不是其他年纪。为了找到最佳分裂节点,分裂算法枚举特征上所有可能的分裂点,然后计算得分,这种算法称为 exact greedy algorithm,单机版本的XGBoost支持这种 exact greedy algorithm,算法如下所示:

为了有效率的找到最佳分裂节点,算法必须先将该特征的所有取值进行排序,之后按顺序取分裂节点计算 。
(2)近似分裂算法
exact greedy algorithm使用贪婪算法非常有效的找到分裂节点,但是当数据量很大时,数据不可能一次性的全部读入到内存中,或者在分布式计算中,这样不可能事先对所有值进行排序,且无法使用所有数据来计算分裂节点之后的树结构得分。为解决这个问题,近似算法被应用进来。近似算法首先按照特征取值的统计分布的一些百分位点确定一些候选分裂点,然后算法将连续的值映射到 buckets中,然后汇总统计数据,并根据聚合统计数据在候选节点中找到最佳节点。具体如下:

对于每个特征,只考察分位点,减少计算复杂度
Global Variant:学习每棵树前,提出候选切分点;Local Variant:每次分裂时,重新提出候选切分点
近似算法举例:三分位数
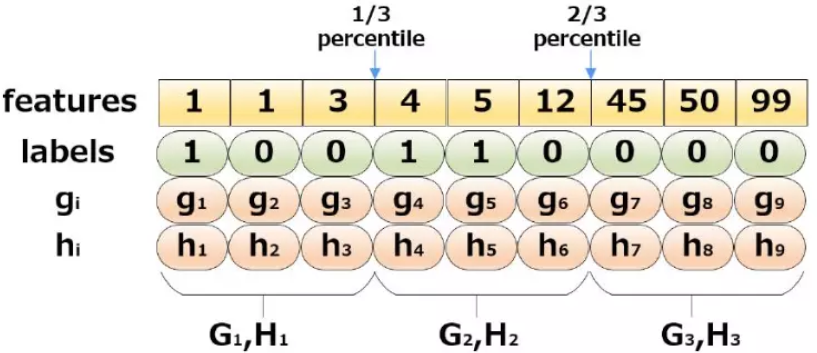
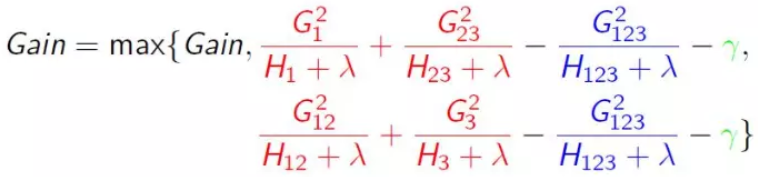
(3)加权分位数(weighted quantile sketch)
在近似算法中的重要步骤中是如何确定候选分裂点。通常特征取值的百分位被用于生成候选分裂点。更进一步的我们可以令多集合
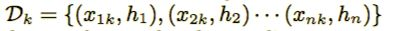
表示第k个特征的每个训练样本的二阶梯度统计,我们可以定义一个排序函数:
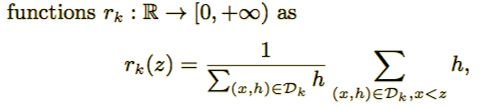
rk(z)表示特征值k小于z的实例比例。目标就是寻找候选分裂点集 。因此
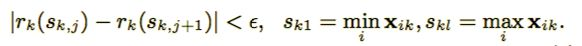
这里 是近似因子,这意味着有大概
个候选点。这里每个数据点的权重为
。
疑问:为什么要用hi加权?
把目标函数整理成以下形式,可以看出hi有对loss加权的作用
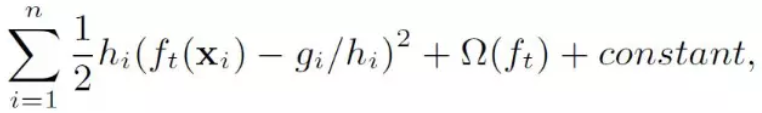
(4)稀疏感知分割
在很多现实业务数据中,训练数据x可能很稀疏。造成这个问题的原因可能是:存在大量缺失值,太多0统计值,one-hot-encoding所致。算法能够处理稀疏模式数据非常重要,XGB在树节点中添加默认划分方向的方法来解决这个问题,如下图所示:

当有缺失值时,系统将实例分到默认方向的叶子节点。每个分支都有两个默认方向,最佳的默认方向可以从训练数据中学习到。算法如下:

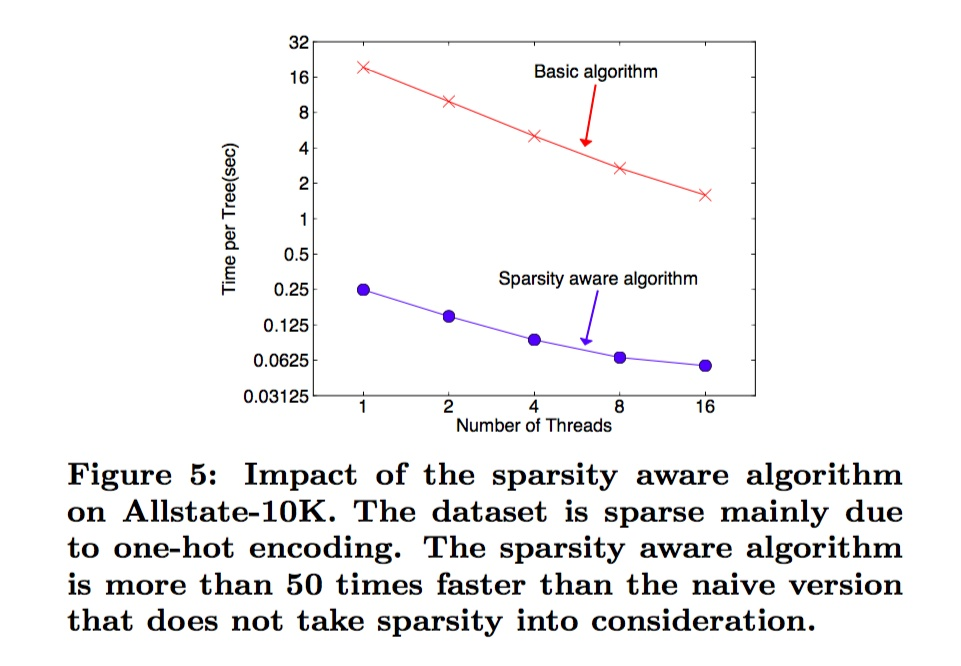
论文中给出了他们的算法在稀疏数据中的处理速度,那是相当的快的
3. Xgboost的参数有哪些,如何调参 ?
(1)General Parameters(常规参数)
- booster [default=gbtree]:选择基分类器,gbtree: tree-based models/gblinear: linear models
- silent [default=0]:设置成1则没有运行信息输出,最好是设置为0.
- nthread [default to maximum number of threads available if not set]:线程数
(2)Booster Parameters(模型参数)
- eta [default=0.3]:shrinkage参数,用于更新叶子节点权重时,乘以该系数,避免步长过大。参数值越大,越可能无法收敛。把学习率 eta 设置的小一些,小学习率可以使得后面的学习更加仔细。
- min_child_weight [default=1]:这个参数默认是 1,是每个叶子里面 h 的和至少是多少,对正负样本不均衡时的 0-1 分类而言,假设 h 在 0.01 附近,min_child_weight 为 1 意味着叶子节点中最少需要包含 100 个样本。这个参数非常影响结果,控制叶子节点中二阶导的和的最小值,该参数值越小,越容易 overfitting。
- max_depth [default=6]: 每颗树的最大深度,树高越深,越容易过拟合。
- max_leaf_nodes:最大叶结点数,与max_depth作用有点重合。
- gamma [default=0]:后剪枝时,用于控制是否后剪枝的参数。
- max_delta_step [default=0]:这个参数在更新步骤中起作用,如果取0表示没有约束,如果取正值则使得更新步骤更加保守。可以防止做太大的更新步子,使更新更加平缓。
- subsample [default=1]:样本随机采样,较低的值使得算法更加保守,防止过拟合,但是太小的值也会造成欠拟合。
- colsample_bytree [default=1]:列采样,对每棵树的生成用的特征进行列采样.一般设置为: 0.5-1
- lambda [default=1]:控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
- alpha [default=0]:控制模型复杂程度的权重值的 L1 正则项参数,参数值越大,模型越不容易过拟合。
- scale_pos_weight [default=1]:如果取值大于0的话,在类别样本不平衡的情况下有助于快速收敛。
(3)Learning Task Parameters(学习任务参数)
- objective [default=reg:linear]:定义最小化损失函数类型,常用参数:
binary:logistic –logistic regression for binary classification, returns predicted probability (not class)
multi:softmax –multiclass classification using the softmax objective, returns predicted class (not probabilities)
you also need to set an additional num_class (number of classes) parameter defining the number of unique classes
multi:softprob –same as softmax, but returns predicted probability of each data point belonging to each class.
- eval_metric [ default according to objective ]:
The metric to be used for validation data.
The default values are rmse for regression and error for classification.
Typical values are:
rmse – root mean square error
mae – mean absolute error
logloss – negative log-likelihood
error – Binary classification error rate (0.5 threshold)
merror – Multiclass classification error rate
mlogloss – Multiclass logloss
auc: Area under the curve
- seed [default=0]:
The random number seed. 随机种子,用于产生可复现的结果
Can be used for generating reproducible results and also for parameter tuning.
注意: python sklearn style参数名会有所变化
eta –> learning_rate
lambda –> reg_lambda
alpha –> reg_alpha
4. Xgboost的优缺点 ?
- 对缺失值的处理,XGBoost可以自动学习出它的分裂方向;
- 支持并行,注意XGBoost的并行不是tree粒度的并行,XGBoost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。XGBoost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),XGBoost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行;
- 近似算法(Approximate Algorithm),树节点在分裂时,需要枚举每个可能的分割点。当数据没法一次性载入内存时,这种方法会很慢。xgboost提出了一种近似的方法去高效的生成候选分割点;
- 除此之外,XGBoost基学习器不仅支持决策树,也支持线性分类器。也就是说,xgboost不仅是一种集成的树模型,也是一种集成的线性模型,也就是带L1和L2的逻辑斯底回归或逻辑回归。所以严格来说xgboost已经不仅仅是GBDT,而是GBM(Gradient Boosting Machine),所以说xgboost这个名字起的非常严谨;
- 除去目标函数自带的正则化项,XGBoost也支持Shrinkage和Subsampling;Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
- 传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
- 列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
- 可并行的近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点
参考文献:
【1】xgboost原理
【2】XgBoost推导与总结
【5】从决策树到XGBoost
【6】Xgboost推导及分析
最新文章
- jQuery选择器和选取方法 http://www.cnblogs.com/MaxIE/p/4078869.html
- SQL Server 复制:事务发布
- selenium多个窗口切换
- IOS开发涉及有点概念&相关知识点
- ie8不支持transform: translateY,ie9支持不友好
- java中synchronized使用方法
- eclipse中使用git进行版本号控制
- Android_WebServices_介绍
- Servlet--ServletInputStream类,ServletOutputStream类
- Java历程-初学篇 Day01初识java
- VMware配置Linux虚拟机访问外网
- sqoop往远程hdfs写入数据时出现Permission denied 的问题
- day 56 jQuery学习
- golang语言基础(一)
- ubuntu时区设置
- Oracle操作ORA-02289: 序列不存在
- 【转】虚拟 IO 服务器(VIOS)和 IBM i
- css3之Media Queries 媒体查询
- 利用docker部署redis集群
- Oracle并发控制、事务管理学习笔记